
本文仅授权过: segmentfault 转载
背景
提供一个短址服务
你有没有发现,我们的任务中出现长 URL 就会比较麻烦?如果有一个短址生成器就好了。虽然市面上有很多,但是我们可以重复发明一个轮子,利用这个机会尝试一下简单的 Web 全栈开发。
任务
做一个短链接生成器,可以将一个长链接缩短成一个短链接。
预览
由 Gigalixir 提供免费部署服务,该地址只用于体验,⚠️ 不提供数据维护存储。
要发车了 🚌
发车前,和大家说一下
如果不想重复的造轮子,想开箱即用,可以使用基于 PHP 的开源软件 YOURLS。YOURLS 还可以和 WordPress 整合到一起,功能强大,可扩展性高。
本文记录了开发短网址系统的整个过程,包括初期的算法调研、模块设计、数据库设计、功能扩展等。
什么是短链接 🔗
就是把普通网址,转换成比较短的网址。比如:http://t.cn/RlB2PdD 这种,在微博这些限制字数的应用里。好处不言而喻。短、字符少、美观、便于发布、传播。
百度短网址 http://dwz.cn/
谷歌短网址服务 https://goo.gl/ (需科学上网)号称是最快的 🚀
原理解析
当我们在浏览器里输入 http://t.cn/RlB2PdD 时
- DNS首先解析获得 http://t.cn 的
IP地址 - 当
DNS获得IP地址以后(比如:74.125.225.72),会向这个地址发送HTTPGET请求,查询短码RlB2PdD - http://t.cn 服务器会通过短码
RlB2PdD获取对应的长 URL - 请求通过
HTTP301转到对应的长 URL https://m.helijia.com 。
这里有个小的知识点,为什么要用 301 跳转而不是 302 呐?
301 是永久重定向,302 是临时重定向。短地址一经生成就不会变化,所以用 301 是符合
http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
来自知乎 iammutex 的答案
算法实现
网上比较流行的算法有两种 自增序列算法、 摘要算法
算法一
自增序列算法 也叫永不重复算法
设置 id 自增,一个 10进制 id 对应一个 62进制的数值,1对1,也就不会出现重复的情况。这个利用的就是低进制转化为高进制时,字符数会减少的特性。
如下图:十进制 10000,对应不同进制的字符表示。
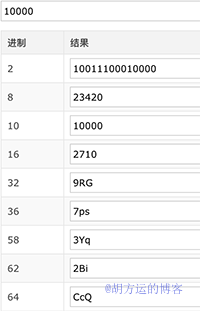
短址的长度一般设为 6 位,而每一位是由 [a - z, A - Z, 0 - 9] 总共 62 个字母组成的,所以 6 位的话,总共会有 62^6 ~= 568亿种组合,基本上够用了。
哈哈,这里附上一个进制转换工具 http://tool.lu/hexconvert/ 上图的数据就是用这个工具生成的。
具体的算法实现,自行谷歌。
算法二
- 将长网址
md5生成 32 位签名串,分为 4 段, 每段 8 个字节 - 对这四段循环处理, 取 8 个字节, 将他看成 16 进制串与 0x3fffffff(30位1) 与操作, 即超过 30 位的忽略处理
- 这 30 位分成 6 段, 每 5 位的数字作为字母表的索引取得特定字符, 依次进行获得 6 位字符串
- 总的
md5串可以获得 4 个 6 位串,取里面的任意一个就可作为这个长 url 的短 url 地址
这种算法,虽然会生成4个,但是仍然存在重复几率
两种算法对比
第一种算法的好处就是简单好理解,永不重复。但是短码的长度不固定,随着 id 变大从一位长度开始递增。如果非要让短码长度固定也可以就是让 id 从指定的数字开始递增就可以了。百度短网址用的这种算法。上文说的开源短网址项目 YOURLS 也是采用了这种算法。源码学习
第二种算法,存在碰撞(重复)的可能性,虽然几率很小。短码位数是比较固定的。不会从一位长度递增到多位的。据说微博使用的这种算法。
我使用的算法一。有一个不太好的地方就是出现的短码是有序的,可能会不安全。我的处理方式是构造 62进制的字母不要按顺序排列。因为想实现自定义短码的功能,我又对算法一进行了优化,下文会介绍。
流程图
自增序列算法流程图
只实现长链接转化为短链接的功能,不是很麻烦。在调研的过程中我发现百度短网址可以自定义短码,我觉的这个功能挺不错,结果复杂度就是上图到下图的变化。😭
自增序列算法 + 用户自定义短码 流程图
百度短网址还允许用户自定义短码,算法二 摘要算法,不和 id 绑定,好像挺好实现这个功能的。
但是自增序列算法是和 id 绑定的,如果允许自定义短码就会占用之后的短码,之后的 id 要生成短码的时候就发现短码已经被用了,那么 id 自增一对一不冲突的优势就体现不出来了。
那么怎么实现自定义短码呐?
我是这样处理的:
数据库增加一个类型 type 字段,用来标记短码是用户自定义生成的,还是系统自动生成的。
如果有用户自定义过短码,把它的类型标记自定义。每次根据 id 计算短码的时候,如果发现对应的短码被占用了,就从类型为自定义的记录里选取一条记录,用它的 id 去计算短码。
这样既可以区分哪些长连接是用户自己定义还是系统自动生成的,还可以不浪费被自定义短码占用的 id
我保留了 1 到 2 位的 短码,从三位的短码开始生成的。就像域名的保留域名一样,好的要自己预留 😏
| 位数 | 个数 | 区间 |
|---|---|---|
| 1位 | 62 | 0 - 61 |
| 2位 | 3844 | 62 - 3843 |
| 3位 | 约 23万 | 3844 - 238327 |
| 4位 | 约 1400万 | 238328 - 14776335 |
| 5位 | 约 9.1亿 | 14776336 - 916132831 |
| 6位 | 约 568亿 | 916132832 - 56800235583 |
数据表设计
links 表
| 字段 | 含义 |
|---|---|
| id | link_id |
| url | 长连接 |
| keyword | 短链接码 |
| type | 系统: “system” 自定义: “custom” |
| insert_at | 插入时间 |
| updated_at | 更新时间 |
后期功能扩展
统计:点击量、访问的 ip 地域、用户使用的设备
管理后台:删除、数据量
登录:权限管理
设置密码:输入密码才可以继续访问
项目源码
使用 Elixir + phoenix 技术栈 short_url